Reflecting on the State of Rehearsal-free Continual Learning with Pretrained Models
Abstract
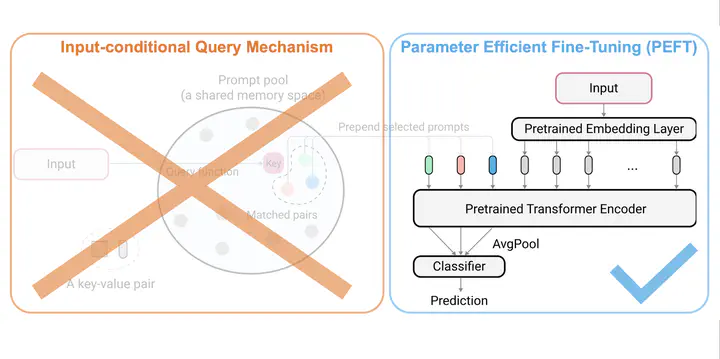
With the advent and recent ubiquity of foundation models, continual learning (CL) has recently shifted from continual training from scratch to the continual adaptation of pretrained models, seeing particular success on rehearsal-free CL benchmarks (RFCL). To achieve this, most proposed methods adapt and restructure parameter-efficient finetuning techniques (PEFT) to suit the continual nature of the problem. Based most often on input-conditional query-mechanisms or regularizations on top of prompt- or adapter-based PEFT, these PEFT-style RFCL (P-RFCL) approaches report peak performances; often convincingly outperforming existing CL techniques. However, on the other end, critical studies have recently highlighted competitive results by training on just the first task or via simple non-parametric baselines. Consequently, questions arise about the relationship between methodological choices in P-RFCL and their reported high benchmark scores. In this work, we tackle these questions to better understand the true drivers behind strong P-RFCL performances, their placement w.r.t. recent first-task adaptation studies, and their relation to preceding CL standards such as EWC or SI. In particular, we show: (1) P-RFCL techniques relying on input-conditional query mechanisms work not because, but rather despite them by collapsing towards standard PEFT shortcut solutions. (2) Indeed, we show how most often, P-RFCL techniques can be matched by a simple and lightweight PEFT baseline. (3) Using this baseline, we identify the implicit bound on tunable parameters when deriving RFCL approaches from PEFT methods as a potential denominator behind P-RFCL efficacy. Finally, we (4) better disentangle continual versus first-task adaptation, and (5) motivate standard RFCL techniques s.a. EWC or SI in light of recent P-RFCL methods.
Lukas Thede
PhD candidate
Lukas is currently pursuing his PhD under joined supervision of Zeynep Akata (at Helmholtz Munich and TUM) and Matthias Bethge (at the University of Tübingen) as part of the International Max-Planck Research School for Intelligent Systems (IMPRS-IS). He obtained his bachelor’s and master’s degrees in Industrial Engineering and Management from the Karlsruhe Institute of Technology (KIT). While studying, Lukas completed internships at Mercedes-Benz in Stuttgart and at Ernst & Young in Berlin.
Matthias Bethge
Professor for Computational Neuroscience and Machine Learning & Director of the Tübingen AI Center
Matthias Bethge is Professor for Computational Neuroscience and Machine Learning at the University of Tübingen and director of the Tübingen AI Center, a joint center between Tübingen University and MPI for Intelligent Systems that is part of the German AI strategy.